GenBank数据库是在科研工作中经常用到的数据库之一,它由美国国家生物技术信息中心(the National Center for Biotechnology Information,NCBI)建立和维护。该数据库包含了所有已知的核酸序列和蛋白质序列,以及与它们相关的文献著作和生物学注释。
小编作为一名有着多年工作经验生信工作者,经常要从GenBank数据库中中下载物种的基因组fasta文件和gbk文件。在小编刚刚入门生信这行时和大多数小伙伴一样使用浏览器一条一条的进行下载,这样的下载方法,对于少量的序列还可以执行,但是如果下载成千上百条序列就成了“灾难”!
最近,小编在学习Biopython模块,发现这个模块下面有子模块可以批量下载GenBank数据库中的fasta文件和gbk文件,小编已经打包成一键化脚本,下面跟小编一起学习一下吧!
脚本运行环境
安装python解释器:安装教程
安装biopython模块
# 使用pip安装
pip install biopython
# 使用conda安装
conda install -c bioconda biopython
准备list文件
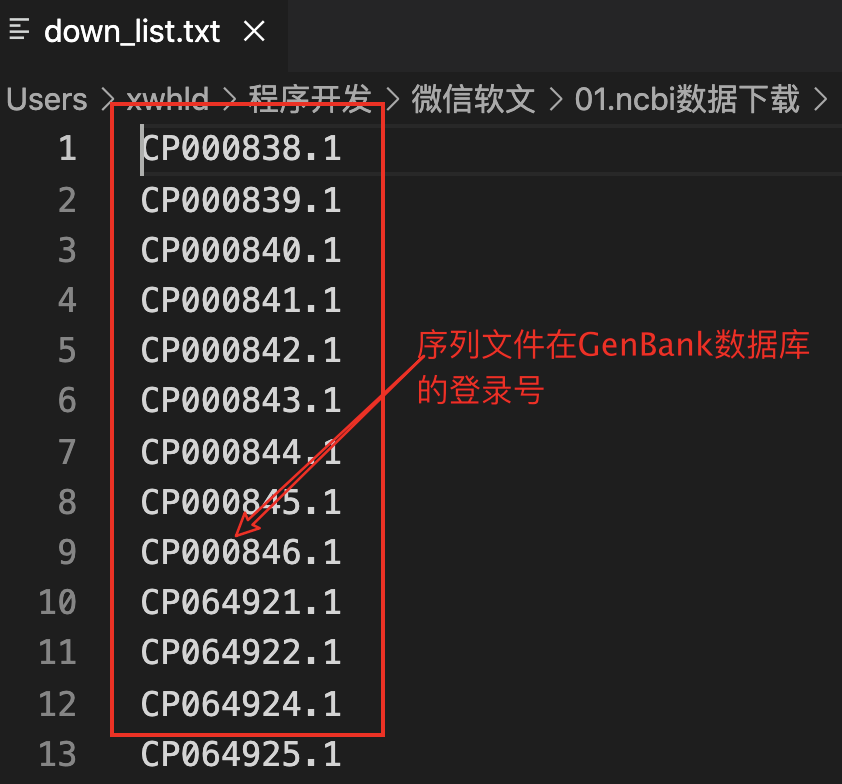
查看脚本参数
python GenBank_download.py -h 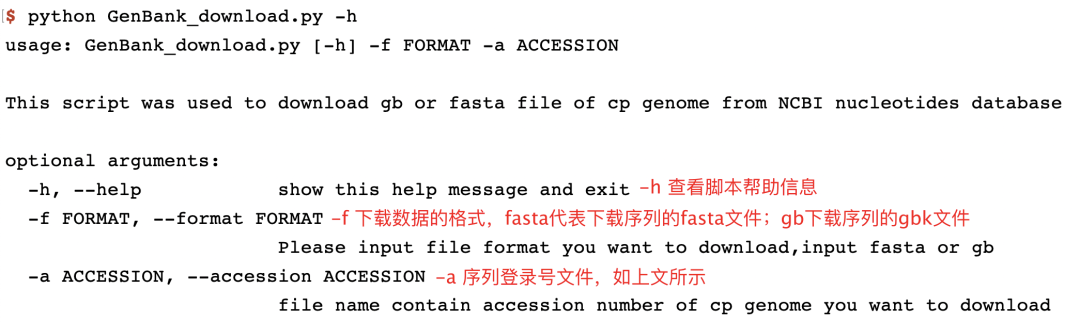
实战演练
# 下载序列fasta文件
python GenBank_download.py -f fasta -a down_list.txt
# 下载序列gbk文件
python GenBank_download.py -f gb -a down_list.txt
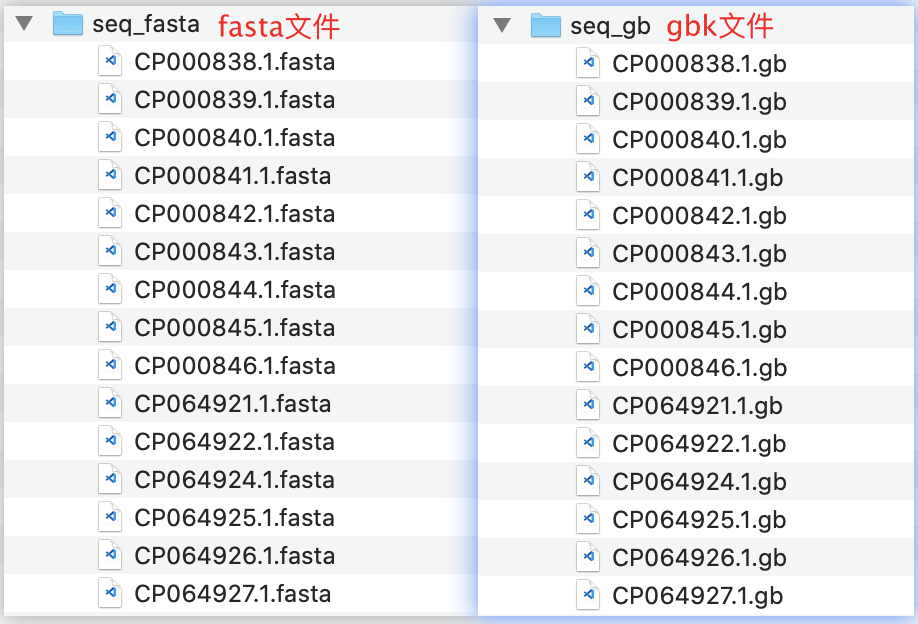
结果展示
注意事项
1、脚本需要依赖于Biopython模块,请提前安装,否则脚本无法运行。
2、脚本只能下载序列的fasta文件和gbk文件,如原核生物基因组fasta文件,无法下载gbk文件中的蛋白序列和CDS序列。
3、对于基因组较大的真核生物,如人基因组,gbk文件有多个染色体组成,不包含基因组fasta文件,这样的序列号无法下载基因组fasta文件。
4、脚本下载序列的gbk文件和fasta文件等同于浏览器下载的gbk文件和fasta文件。








