当我们下载大量的gbk文件时,我们可以从gbk文件中提取蛋白质序列,CDS序列,tRNA以及rRNA序列,以便于下载对这些序列做进一步的分析,如进行找同源单拷贝基因,基于16SrRNA构建进化树等等。
这次分享的脚本是从gbk文件中,提取蛋白质以及蛋白质质对应的注释信息。
脚本运行环境
安装python解释器:安装教程
安装biopython模块
# 使用pip安装
pip install biopython
# 使用conda安装
conda install -c bioconda biopython查看脚本参数
python gbk_extea_protein.py -h 
实战演练
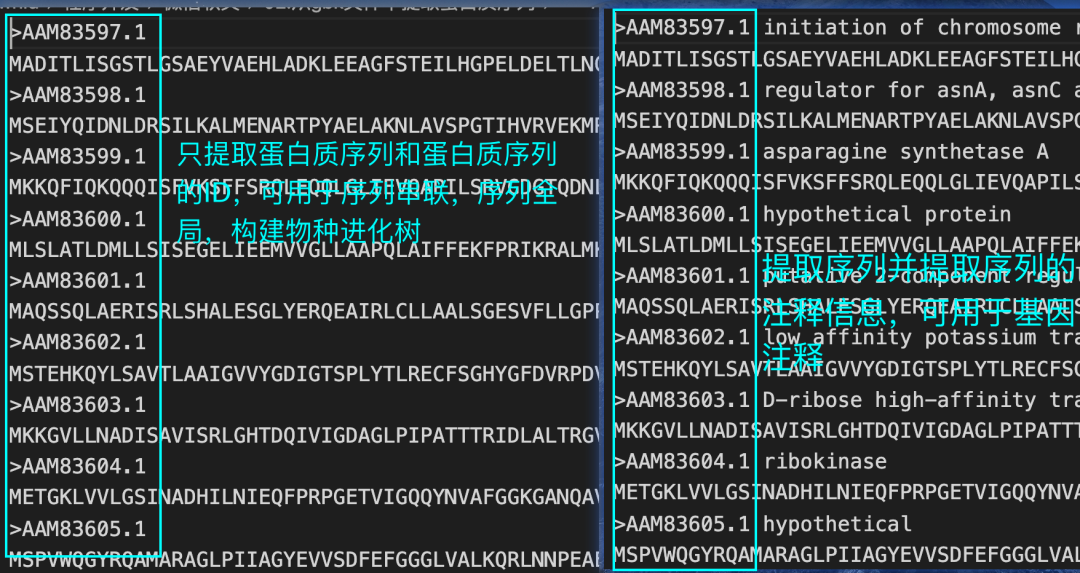
# 只提取蛋白质序列和蛋白质ID
python gbk_extea_protein.py -g AE009952.gbk -a F -o AE009952.fna
# 提取蛋白质序列以及序列的注释信息
python gbk_extea_protein.py -g AE009952.gbk -a T -o AE009952.faa
结果展示
注意事项
01脚本需要依赖于Biopython模块,请提前安装,否则脚本无法运行。
02对于基因组较大的真核生物,如人基因组,gbk文件有多个染色体组成,不包含蛋白序列文件,这样的gbk文件无法使用脚本提取蛋白质序列。
03有些gbk文件,作者在上传gbk文件时,没有公开蛋白质序列以及蛋白质注释信息,这样的gbk文件无法使用脚本提取蛋白质序列。








