我们今天分享一种快速提取序列的方法:一个从FASTA文件中提取特定序列的脚本。
除了一些复杂的软件能够完成上面的需求之外,另外一种非常方便快捷的方法就是使用编程。虽然大部分研究人员都不懂编程,但使用编写好的脚本,按图索骥,还是非常简单的。今天给大家分享的是一段python脚本。
如果Windows(或Mac)电脑上尚未安装Python语言,可以直接下载安装,这里提供两种下载方法:
①Python官方下载渠道:https://www.python.org(访问较慢)
②关注(微信公众号密码子实验室)并回复“Python安装包”,即可高速下载最新版本。
Python的安装使用
目前最新稳定版本是3.8.5版本,本文以64位版本为例安装。
Pyt
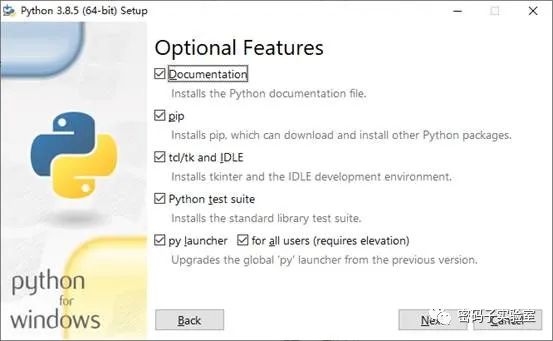
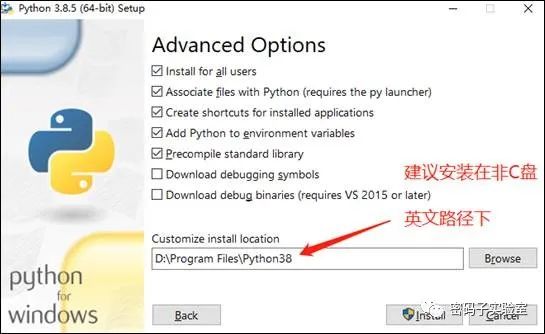
脚本的使用
python运行环境检测
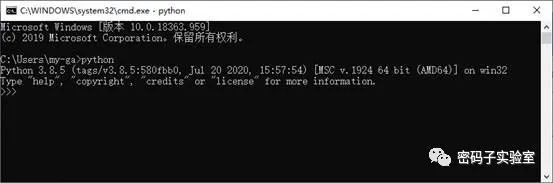
方法① 使用快捷键“win+R”(windows键就是键盘上Ctrl和Alt键之间的带有微软windows标志的按键),输入cmd,点击“确定”,调出DOS操作界面,输入“python”即可看到安装的版本。

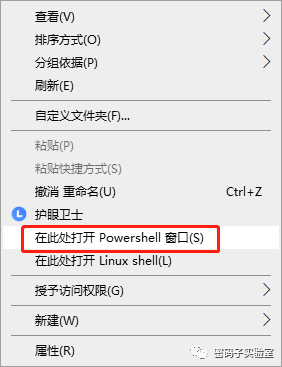
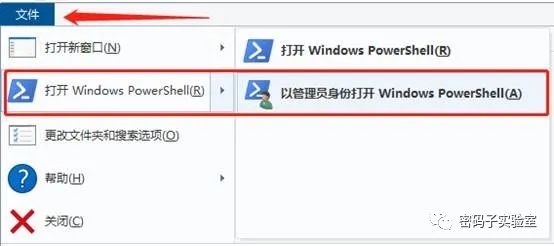
方法② 在目标目录文件夹下(实际上可以是任意文件夹下),按住“Shift”键,同时右击鼠标,弹出菜单中选择“在此处打开Powershell窗口,或者在当前文件夹下,点击本文件夹最左上角的“文件”菜单,选择“打开Windows PowerShell”,在弹出的界面中输入“python”获取相关信息。
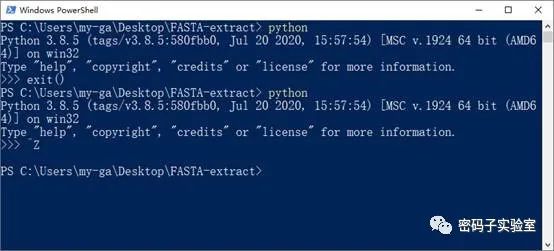
提示:可以输入“exit()”然后按回车键退出,或者按住“Ctrl+z”然后按回车键退出。
3、文件准备
本脚本的数据源包括两个,一个是包含了各条基因序列的FASTA文件,一个是含有目的基因名称的list文件。源序列文件建议使用fasta、fna或者fa等常见后缀,list文件建议使用记事本生成txt后缀文件或者使用word文档保存成txt后缀文档。
本文中以从GenBank中下载的一个基因组CDS核酸序列为例展示,并将基因序列号做了重新编排。
Tips:
①基因组fasta文件往往比较大,推荐大家使用UltraEdit或者NotePad++软件打开这类大文件,会很顺畅不死机,如果需要序列号授权版请在留言区联系我们;
②对于DOS操作系统不熟悉的用户往往会因文件路径问题而抓狂,为了简化文件路径,建议大家把脚本文件、FASTA源文件、含有目标序列名称的list文件放在同一个目录下,最后的结果文件也生成在该目录下;
③ 如果对于数据文件下载、源文件格式、list文件格式等有疑问,可以单独联系小编(微信号:15618204007)。
4、脚本使用
本脚本的使用方法是,在DOS界面(实际上在Linux系统中也是一样方法)中输入“python -help”,然后回车即可获得使用方法。
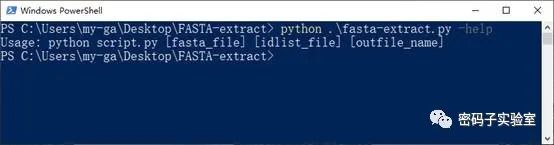
实战操作:
在PowerShell或者命令提示符界面输入“python .\fasta-extract.py .\test.fasta .\test-list.txt .\test-result.fasta”,回车即可获得结果文件。


说明:
①输入“python”是开始调用已安装的python程序,在DOS系统中,也可以使用“python.exe”,效果是一样的;
②文件名前加“.\”表示当前目录下,如果是其他路径,可以直接输入绝对路径;
③ list文件中的序列名称,必须与源文件中相应的序列名称完全一致,否则不能识别和有效提取。
>>
上海唯那生物专注于提供微生物包括耐药性研究在内的各类个性化服务,包括基金方案申报、组学测序、个性化生信分析、文章辅导发表、科研绘图、微生物纯化培养、基因克隆、微生物突变体(库)构建等。全方位,一站式,我们期待与您的合作。从数据处理、相关运算,到结果解读、图片绘制,全方位、一站式提供相关研究的解决方案,大家有需要的话也请联系我们。








